
Expert Systems: What Can We Learn from its Rise and Fall
From those rhyming themes of two AI booms lie inspirations and lessons we can draw.

Artificial intelligence encountered two major winters in its less-than-a-centory history. After the first AI winter in the 1970s, there was a short AI boom in the 1980s - an era marked by the rise, peak and fall of expert systems. During the rise, expensive specialized hardware like “LISP machines” for running expert systems were successfully commercialized. National level initiatives to build the foundational infrastructure were created, including Japan’s 10-year plan to build the fifth generation computer to leapfrog the west. There were concerns about displacement of white collar jobs, and widening gaps between the haves and havenots. Its fallout of favor, however, caused the second AI winter that only started to recover in the 2000s. How did expert systems gain popularity and hypes, and why did they lose traction and eventually fall out of favor?
Like most of you, I am not old enough to have lived through that part of history. However, if we take a glimpse into some key historical materials from that time and compare them with the current AI boom, we can still see lots of rhyming themes. From those rhyming themes lie inspirations and lessons we can draw.
For the materials referenced in this article, please visit the references section for links.
Expert Systems vs LLM Agents
What is an expert system? According to [4], an expert system is “an AI program that achieves competence in performing a specialized task by reasoning with a body of knowledge about the task and the task domain”.
The following chart from [1] captures the major components of an expert system, and the external components that it interacts with when it is being built or used.
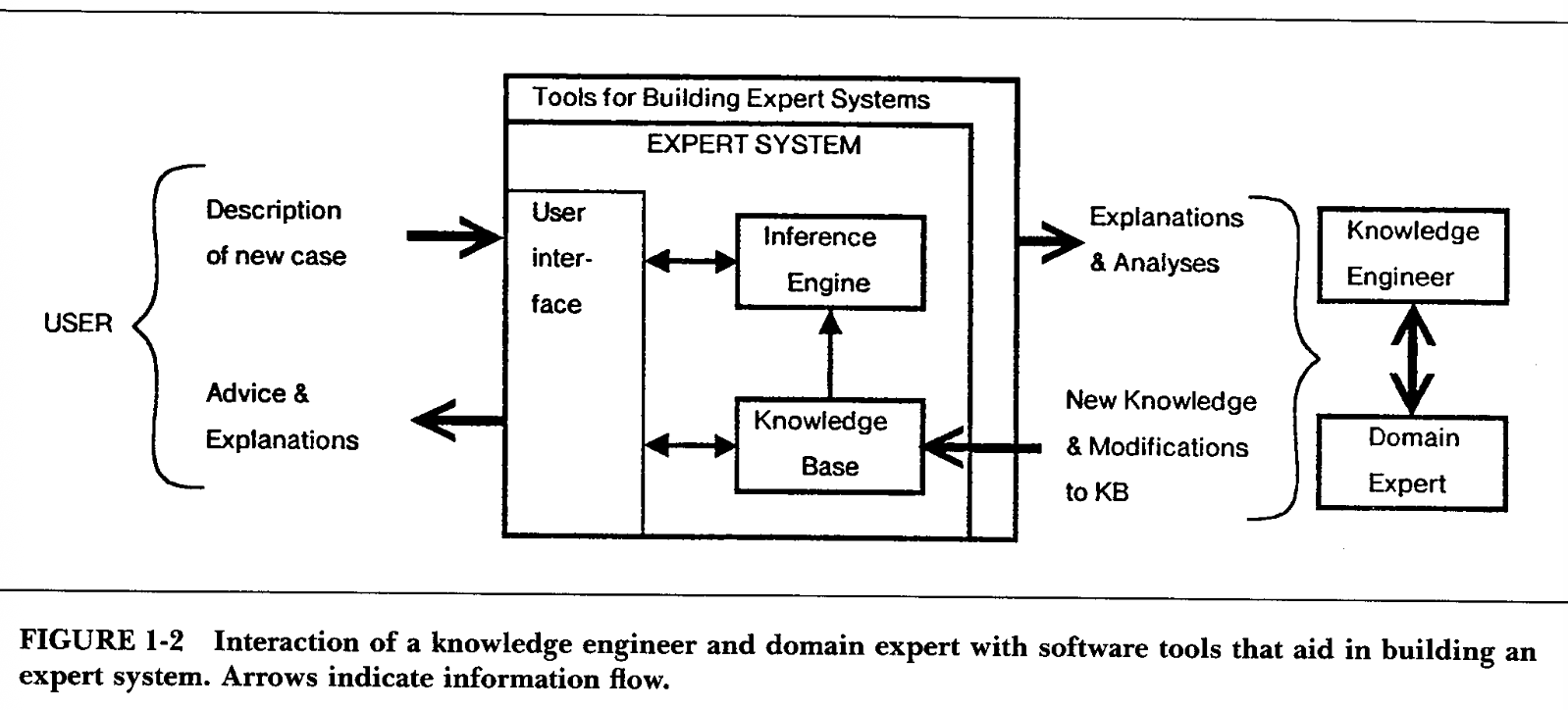
How is an expert system different from a conventional computer program? The NASA report [2] summarized it pretty well:
In a conventional computer program, knowledge pertinent to the problem and methods for utilizing this knowledge are all intermixed, so that it is difficult to change the program. In an expert system, the program itself is only an interpreter (or general reasoning mechanism) and [ideally] the system can be changed by simply adding or subtracting rules in the knowledge base.
Interestingly, if you do a few small tweaks to the chart, e.g. replacing “Inference Engine” with “LLM” and replacing “Knowledge Base” with “Context”, etc, you will get a chart that pretty much captures how LLM agents work today:
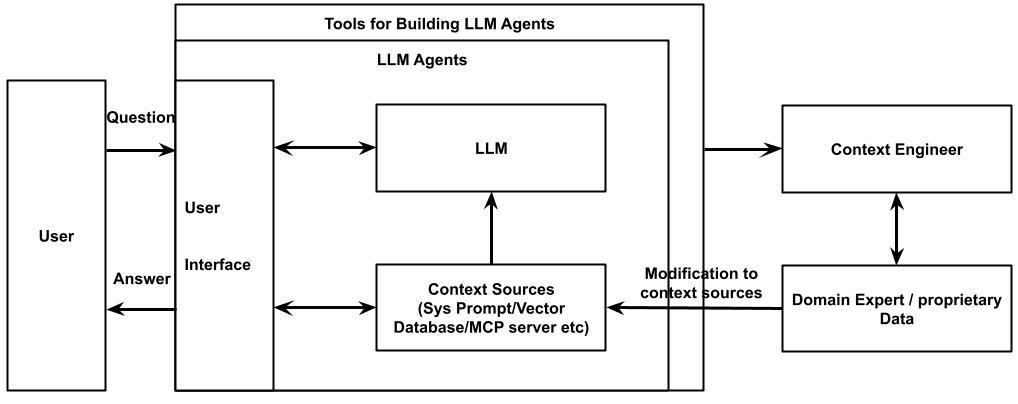
And how is a LLM agent different from a conventional machine learning system? We can similarly make a small edit to the NASA report and it will just work perfectly:
In a conventional machine learning system, information pertinent to the problem and models for utilizing this information are all intermixed, so that it is difficult to change the ML system. In an LLM agent, the LLM itself is only an interpreter (or general reasoning mechanism) and [ideally] the system can be changed by simply adding or subtracting information in the context.
Of course, it would be pretty naive to conclude that LLM agents are just old wine in a new bottle and that’s definitely not my conclusion. However, such a comparison will help us find matching components of the two systems, from which we ask deeper questions. For example, what is the fundamental difference between LLM and inference engine, or between context engineering and knowledge engineering? What similar or different outcome can we expect?
Context Engineering vs Knowledge Engineering
I have seen the following argument from lots of articles. The argument is that LLMs are already very smart, maybe smarter than most humans, however, the problem is that most of us just don’t know how to give it the right context and therefore we need more people to become good prompt engineers, or, context engineers.
In the expert systems era, there was a similar, popular role called knowledge engineer, whose job was to work with domain experts to extract and structure information into facts and rules to build the knowledge base. Anyway, the inference engine is a general purpose reasoning engine; what we need is just feeding the domain knowledge to get it going, right?. LLMs crave for “context”, and inference engines crave for “knowledge”. That crave for “knowledge” was very well stated in [3]:
As the pressure builds to apply artificial intelligence to a variety of expert system projects, a new industry (now in its infancy) will emerge… This new “knowledge engineering” industry will transfer the developments of the research laboratories to the useful expert systems that industry, science, medicine, business, and the military will be demanding … Limiting the pace of development of this industry will be the shortage of people — the new knowledge engineers.
As we all know, that new “knowledge engineering” industry didn’t boom as anticipated in the paper; so was the demand for “knowledge engineers”. The fundamental problem is the need for knowledge engineering itself. Since the inference engine couldn’t acquire knowledge itself, it needed knowledge engineering from the external; however, lots of knowledge is too subtle to be coded explicitly as rules, and even in areas it can be coded, there isn’t much value left after the intensive knowledge engineering and maintenance. In other words, the limit of presenting knowledge and past experiences as explicit rules and the lack of self learning capabilities greatly limited expert systems’ applications.
Today’s LLMs alleviate the need for exact rule distillation and have the capability of doing reasoning leaps, but they have similar limitations to inference engines. They need us to pass the context mostly in natural language format and they can’t discover and track their context themselves. However, lots of knowledge, past experiences and current situations can’t be coded explicitly as natural languages. Drawing lessons from expert systems, one question to be answered about today’s LLM Agents would be, what kind of knowledge and situation can be economically engineered as context consumable by LLMs, and which applications would have enough residual value after context engineering and maintenance? Applying to the right areas would be the key to the success of LLM agents.
To take a step further, if we want today’s LLM agents to overcome those limitations, we need them to be able to self-learn. At that point, the limit of language goes away - the agents will have their internal representation of accumulated knowledge and current situations, while language is only a way for external communication. Self learning was an articulated yet unfulfilled goal during the expert system era, and it would need to be the goal for the next generation agents as well.
The Peak, Fall and Resurrection
Written by Edward Feigenbaum, a Turing Award winner and the “father of expert systems”, The Rise of the Expert Company [4] was published in 1988 at the peak of optimism of expert systems. After covering various success stories with expert systems, Feigenbaum talked about broader ecosystem and societal implications, including slow adoption due to inertia, national infrastructure through government funding, potential job displacement caused by productivity boosts, legal issues around ownership of worker knowledge, and widening gap between knowledge haves and have-nots. All of them should sound very familiar if you pay attention to current discussions on AGI.
As we all know, those concerns were largely non-issue. In the first decade of the 21st century, when the field started to recover from the AI winter, there was actually a resurrection for the technology under the name “rule based systems” with significant success. At that time, it just became a normal technology that no longer attracted hypes.
The Library of the Future
In his book, Feigenbaum called for the second era of knowledge processing, where people can talk to expert systems through natural language, and expert systems will have common sense, with the ability to generalize and self learn. Retrospectively, Feigenbaum knew very well what problems needed to be solved; what was wrong was that he thought they could be solved within the expert system framework.
The part of the book that I found most fascinating though, is a section titled “The Library of the Future”, where Feigenbaum imagined a world of an abundance of knowledgeable assistants (the “library”) in the year 2030.
It acts as a consultant on specific problems, offering advice on particular solutions, justifying those solutions with citations or with a fabric of general reasoning.
It pursues paths of associations to suggest to the user previously unseen connections. Collaborating with the user, it associates and draws analogies to “brainstorm” for remote or novel concepts.
The user of the library of the future need not be a person. It may be another knowledge system - that is, any intelligent agent with a need for knowledge. Such a library will be a network of knowledge systems, in which people and machines collaborate.
If we don’t stress too hard on correctness of reasoning and truly novelty of concepts, it looks like Feigenbaum’s imagination is indeed coming to reality?
References
[1] Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project, by Edward H. Shortliffe in 1984. Shortliffe was the principal developer of the clinical expert system MYCIN, an early rule-based expert system that showed their potential to obtain superhuman expertise and greatly motivated later development of the area.
[2] An Overview of Expert Systems, a technical report from NASA in 1982.
[3] Expert Systems in the 1980s, by Edward Feigenbaum, who is a Turing Award winner and is often considered “the father of expert systems”.
[4] The Rise of the Expert Company, also by Edward Feigenbaum, published in 1988, where the author painted a very optimistic vision of expert systems and artificial intelligence in general.